



谷歌 I/O 大会前夕曝光新模型 Omni,视频生成能力即将升级?

 Win下载
Win下载
 Mac下载
Mac下载
谷歌似乎正在筹备一款名为 “Omni” 的全新 Gemini 视频生成工具。近期曝光的一张 Gemini 视频生成标签页的截图中出现了这样一行文字:“从一个创意开始,或套用模板。由 Omni 提供技术支持。”
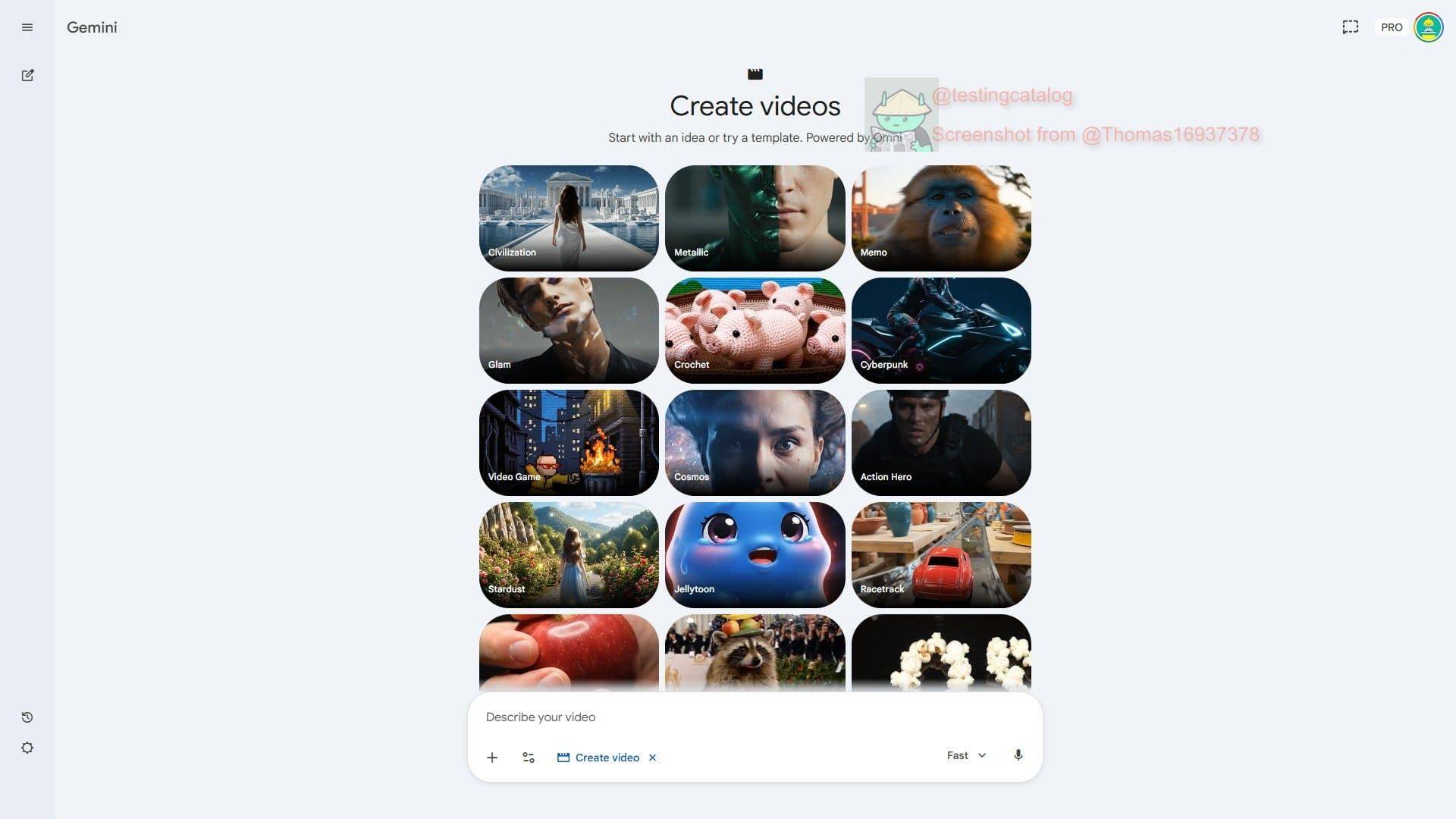
这一细节的位置颇具深意:Omni 出现在了现有工具“Toucan”的旁边。Toucan 是目前仍在运营的视频生成工具,由 Veo 模型驱动,早在 2025 年谷歌开发者大会(I/O)之前就被外界发现。
模型策略从分立到统一?
目前,Gemini 的视频生成流程主要由 Veo 3.1 提供支持,而图像生成则依托于 Nano Banana 2 和 Nano Banana Pro 两大模型。谷歌介绍称,Nano Banana Pro 基于 Gemini 3 打造,而 Nano Banana 2 则由 Gemini 3.1 Flash Image 驱动。
目前尚存一个疑问:Omni 究竟是 Veo 模型的全新封装版本、一款独立的 Gemini 视频新模型,还是谷歌迈向“全能大模型”的早期布局,即未来可在同一系统内统一处理图像与视频生成任务?
由于 Omni 已经出现在界面可见的文字文案中,而不仅仅存在于后台隐藏代码里,它很有可能会作为正式面向公众的产品名称推出。
如果传闻属实(目前仍属于高度推测),Gemini 将成为首款支持视频输出的顶级全能大模型!
谷歌当前采用的是模型分拆策略:视频生成交由 Veo 负责,图像生成则由基于 Gemini 的 Nano Banana 系列模型承担。而 Omni 有望将这两大技术赛道整合打通。这也正值 AI 视频领域的竞争白热化之际,字节跳动的 Seedance 2.0 目前在视频生成基准测试中占据榜首。
业内重点关注的预计发布时间窗口为 2026 年谷歌开发者大会。谷歌已官宣本届大会将于 5 月 19 日至 20 日举办,届时将发布 Gemini 及全线 AI 产品更新,这也为谷歌重磅揭晓 Gemini 多媒体生成新功能提供了绝佳舞台。

 有用
有用

















