



OpenAI 全新 GPT-5.5-Cyber 漏洞基准测试超越 Claude Mythos 5

 Win下载
Win下载
 Mac下载
Mac下载
OpenAI 宣布大规模扩容黎明计划(Daybreak)—— 该网络安全专项项目旨在帮助研发团队在软件开发早期阶段完成漏洞的发现、核验与修复工作。
高性能 AI 大模型的问世彻底改变了网络安全行业格局,漏洞挖掘效率得到大幅提升。但如今行业面临更棘手的瓶颈:漏洞修复环节。软件开发团队需要核验已发现风险、评估漏洞影响范围、编写修复方案、完成测试并上线安全补丁。
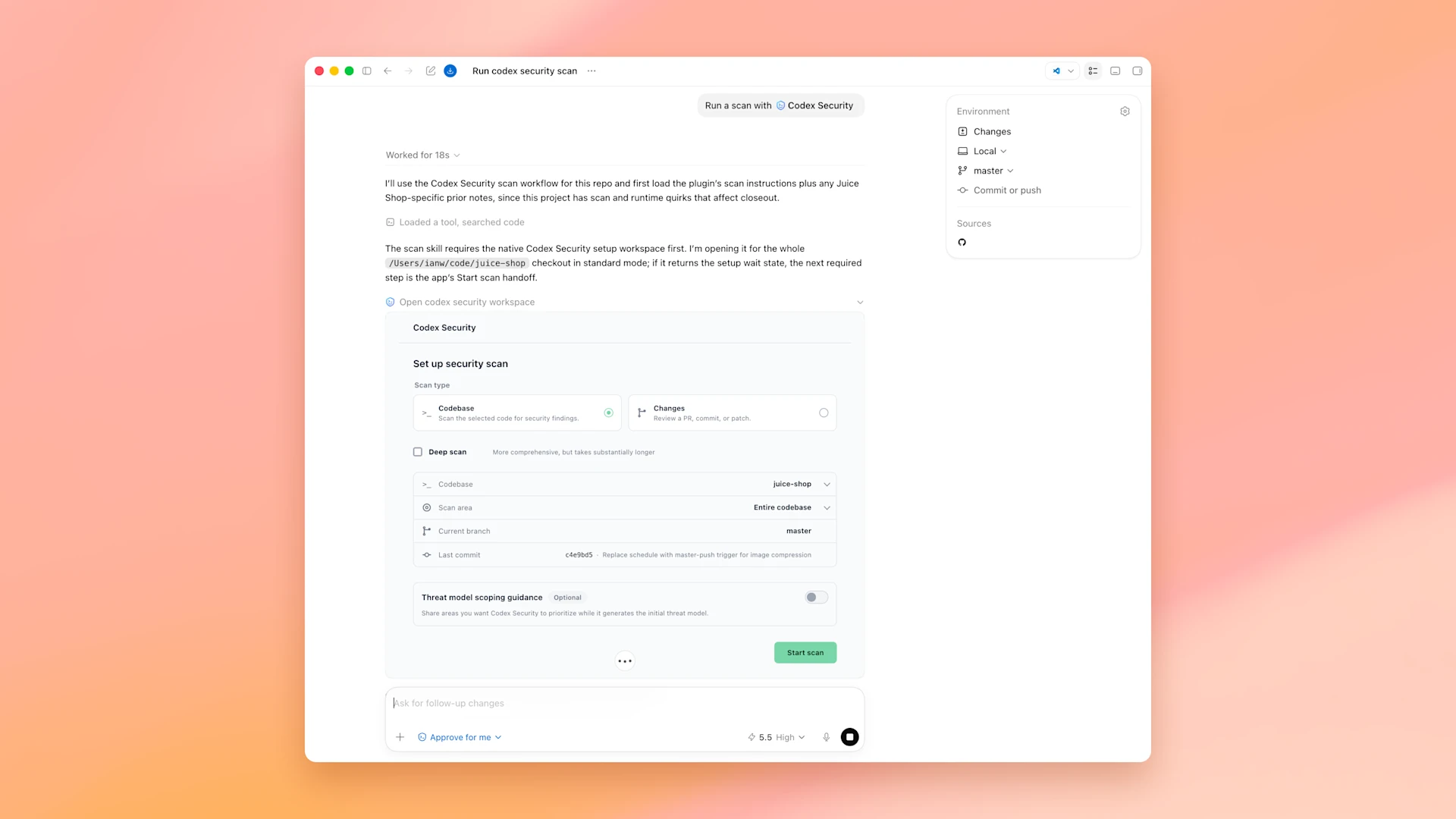
早在今年 3 月,OpenAI 就上线了 Codex Security 预览版工具。该工具依托智能代理推理能力搭配自动核验机制,可针对特定代码库挖掘高危安全隐患,并生成可落地的修复方案。上线至今,它已完成超 3 万套代码库、总计 3000 万次代码提交记录扫描。人工审核人员标记修复的漏洞超 7 万处,另有超 50 万处漏洞被系统自动判定为已修复。
如今 OpenAI 发布升级后的 Codex Security 插件,新增以下能力:
深度全域代码扫描
增量校验代码近期变更内容
自动生成安全检测报告
梳理还原完整攻击链路
核验漏洞有效性
生成适配对应代码库的补丁,供人工复核
整合分类第三方扫描工具、安全规范、漏洞赏金报告、工单系统产出的各类风险条目
通过 SARIF 文件、CodeQL 查询语句、Codex 命令行工具、Codex 客户端完成结果导出,兼容各类漏洞管理系统、接入现有研发工作流
2026 年 5 月,OpenAI 公布 GPT-5.5-Cyber 预览版。该模型基于刚发布的 GPT-5.5 打造,专为网络安全专业场景定制。如今 OpenAI 面向合规安全从业者限量正式上线完整版 GPT-5.5-Cyber。
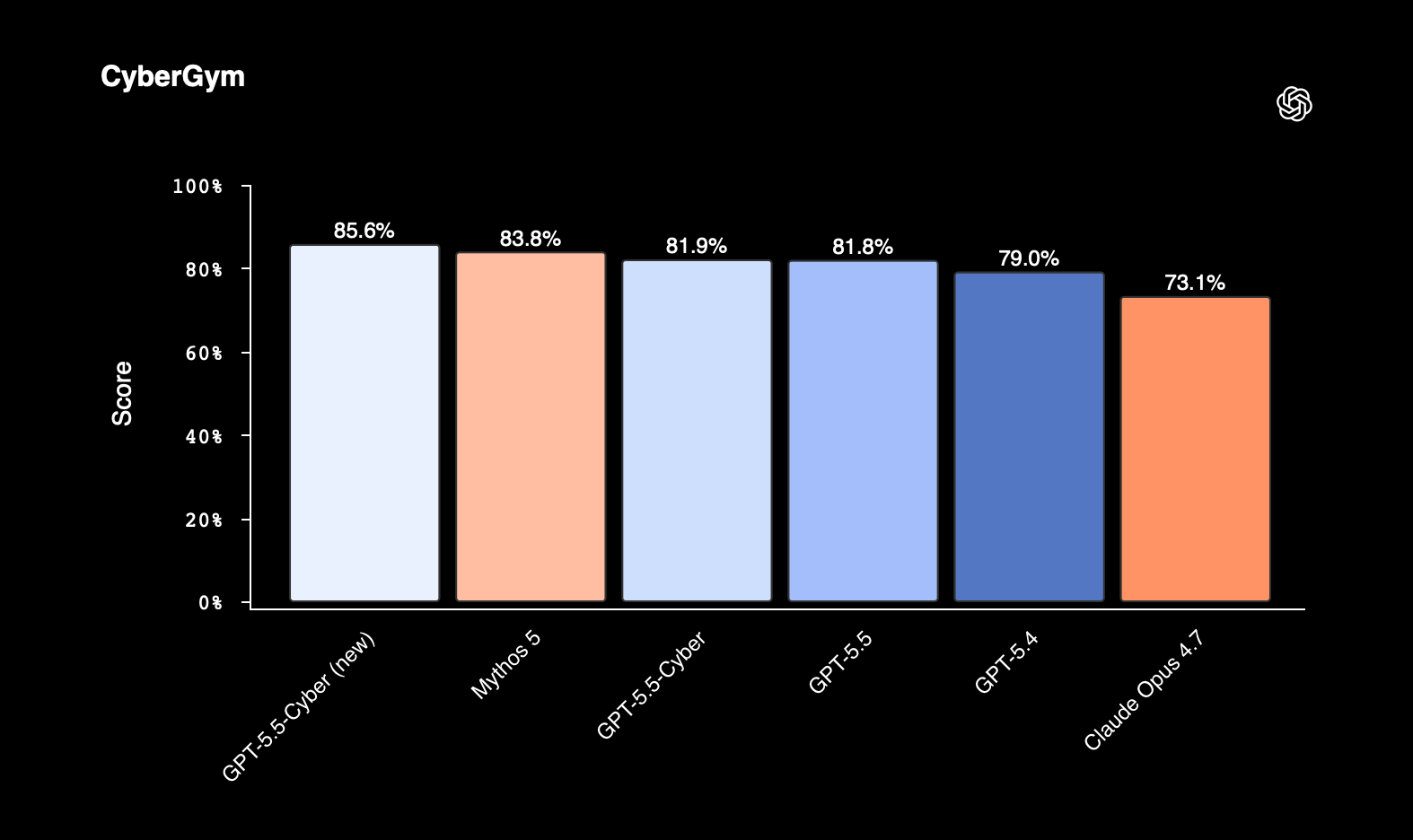
在 CyberGym 安全评测中,GPT-5.5-Cyber 得分 85.6%;作为对比,通用版 GPT-5.5 得分 81.8%,Claude Mythos 5 仅 83.8%。
漏洞利用测试集 ExploitGym 中,GPT-5.5-Cyber 达到 39.5%,而原版 GPT-5.5 仅 25.95%。
专业安全基准 SEC-bench Pro 评测里,新模型得分 69.8%,通用 GPT-5.5 为 63.1%。
OpenAI 同步推出黎明网络安全合作伙伴计划(Daybreak Cyber Partner Program),安全软硬件服务商可在自有产品与服务中,搭载具备网络安全可信访问权限的 GPT-5.5 模型。首批合作企业包括埃森哲、阿卡迈、思科、Cloudflare、科来斯特瑞克、IBM、派拓网络、普福点、哨兵一号、Wiz、思杰等厂商。
OpenAI 还联合 Trail of Bits、HackerOne、Calif、安全研究员及开源项目维护方,发起名为 “全球补丁行动(Patch the Planet)” 的公益项目。已有 30 余个开源项目确认参与,包含 cURL、Go 语言、Python、Sigstore、pyca/cryptography 密码库等知名开源工程。

 有用
有用

















